
QWERTY for Characters
A Conceptual Overview of the Tsāhng-jyéh Input Method Within the Context of Hwayih Woen

Introduction
For speakers of English—or indeed any alphabetic language—computer keyboards, as well as their typewriter predecessors, are intuitive devices to understand. Each letter of the alphabet resides on a keycap, and when the typist wishes to write a word, he simply pushes the relevant buttons in the necessary sequence, thereby manually compiling the word by his own analog efforts. However, when faced with a writing system that requires several thousand unique characters just for the most basic forms of literacy, such a simplistic mechanism, by direct comparison, becomes woefully impractical.

How Chinese computer engineers retrofitted Chinese characters onto the standard QWERTY keyboard during the latter portion of the twentieth century was actually the subject of the Hwayih Woen white paper’s fourth part, which is available to read at the link below:

However, for the sake of brief summary, it is temporarily sufficient to say that Chinese keyboard layouts—or “input methods,” more precisely speaking—subdivide into two general categories—phonetics-based and appearance-based. In the context of the former, the typist uses phonetic symbols—most commonly the letters of the Latin alphabet—to represent the sound of the word that he wishes to write, and then the computer algorithmically ascertains how that word is represented in characters, which of course offers intuitive ease-of-use, but requires the typist to actually know the language to which the word belongs.
Conversely, appearance-based input methods operate by constructing a character from constituent components that are assigned to various positions on the keyboard. Because of this disconnect between sound and appearance, any speaker of any language can use them. Consider, by way of comparison, how a monolingual anglophone can still do data entry for languages as disparate as Italian or Indonesian despite knowing nothing about those languages simply because they all use the same letters on the same keyboard. In other words, alphabetic spelling removes linguistic understanding as a requirement for keyboard typing.
The oldest keyboard layout among these appearance-based systems is the Tsāhng-jyéh Input Method1 (仓颉输入法), which is the recommended system for monolingual anglophones aspiring to type Hwayih Woen on the computer.
Core Barriers to Entry
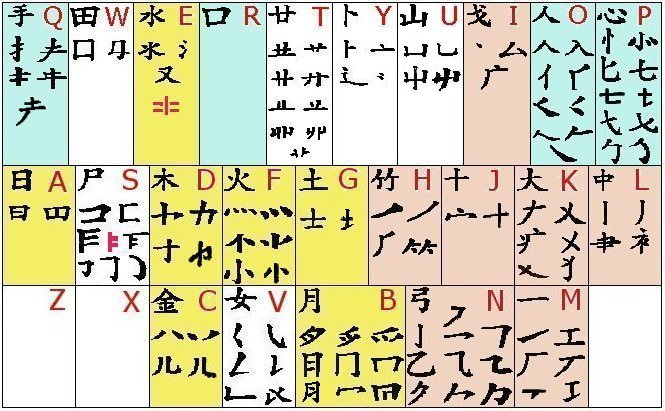
According to the architecture of the Tsāhng-jyéh Input Method, all Chinese characters can be constructed out of a common set of—according to the current count—137 components, which are in turn subdivided and grouped into 24 clusters, with each cluster occupying one of the lettered keycaps on the standard QWERTY keyboard (with the exception of the X and Z keys, which have no cluster assigned to them). This, in theory, would make typing a Chinese character as simple as spelling an English word, and in many cases, it is. However, due to the complexity that a single Chinese character can often contain, the Tsāhng-jyéh Input Method—in order to maintain a high level of data entry efficiency—limits input of any Chinese character to a maximum of five keystrokes. Obviously, because many Chinese characters contain more than five components, this imposes a requirement upon the typist to know which components to omit when writing on a keyboard. Fortunately, the omissions are not random. Unfortunately, the rules governing omissions are multi-layered and therefore somewhat convoluted.
However—by a stroke of historical luck—the abject chaos of the English spelling system cultivates within the anglophone mind a degree of mental flexibility that enables one to memorize and retain exceedingly haphazard lexical deconstructions. Consider, by way of example, how the English language expects its users to make reliable mental distinctions between words like though, trough, through, thorough, and thought. The key to operationalizing this expectation is the existence of an authoritative reference point. Indeed, it is highly unlikely that English spelling conventions could have lasted as long as they have without the proliferation of dictionaries mass produced by Gutenberg’s printing press.2
On the internet today, there does exist a wide array of reference tools to ascertain the input codes for a given character, and some of them even use color coding to indicate which specific components within a given cluster are anchoring the input sequence, and which components are being omitted. However, not only are these databases frequently incomplete, almost a third of the 137 Tsāhng-jyéh components—at the time of this writing—do not exist in Unicode at all, which makes listing keystroke sequences an extremely unreliable affair. In the vast majority of instances, a Tsāhng-jyéh lookup dictionary will at most provide the keycap letter that identifies the relevant cluster, but leave wholly ambiguous which component within the cluster is being used, because there’s simply no reliable way to digitally represent it.
To address this issue, Sinology Unbound has assigned to each of the 137 components a unique tag, which enables individuals who have an extremely shallow understanding of the Tsāhng-jyéh omission rules to nevertheless ascertain the relevant components behind each keystroke in a character’s input code. When compiled together, these tags combine to create a unique serial number that can simultaneously identify any Chinese character within the Unicode set in addition to its constituent components.
To view the comprehensive component chart, please click the link below.
Caveat Lector
The objective of this exposition is to simply explain how to read and comprehend the serial number input codes. This is not a comprehensive pedagogy concerning the tangibility of the Tsāhng-jyéh Input Method itself. Such a task must necessarily be reserved for a formalized typing curriculum that will eventually be made available to the public.
Conceptual Overview
To understand the anatomy of the tag system, one must first understand the anatomy of the Tsāhng-jyéh keyboard layout itself.

Each of the 26 letter keys are assigned an identifying character. Typing any of these characters is as simple as typing an English letter. To type 日, one simply presses the A key. To type 月, one simply presses the B key, and so on and so forth.
Furthermore, this “base layer” alone is frequently sufficient to input multi-component characters, too.
By way of illustration, consider the following Junior Script examples and their respective input codes:
a as in ax【嵓】
(山)u00(口)r00(口)r00(口)r00e as in etch【埜】
(木)d00(木)d00(土)g00t as in batman【夳】
(大)k00(一)m00(一)m00ck as in backgammon【峇】
(山)u00(人)o00(一)m00(口)r00etc.
From these examples, one may see that the keycap character in parentheses along with the lowercase letter identifies the keystroke, and the double digit number identifies which component within the cluster is being used.
However, in the vast majority of instances, a typist will need to call upon multiple different layers within the component clusters in order to type a character. For this reason, the double digit number within each tag expels any ambiguity.
By way of illustration, consider the following Junior Script examples and their respective input codes:
a as in aches【盃】
(一)m00(火)f03(月)b06(廿)t05e as in each【籴】
(人)o01(火)f04(木)d00t as in ton【涾】
(水)e02(水)e00(日)a00k as in kiddie【偘】
(人)o02(口)r00(口)r00(口)r00etc.
The anatomy of the input code is always unambiguous, regardless of whether one is writing in Junior Script or Senior script. By way of illustration, consider the following Senior Script examples taken from the Hwayih Woen edition of McGuffey’s First Eclectic Reader:
boy【囝】
(田)w01(弓)n03(木)d03cat【猫】
(大)k04(竹)h02(廿)t02(田)w00dog【狗】
(大)k04(竹)h02(心)p08(口)r00girl【囡】
(田)w01(女)v00thing【事】
(十)j00(中)l00(中)l03(弓)n02etc.
From these examples, one may see that components like b06, d03, f03, f04, and k04 do not exist in Unicode, but because of the standardized tags, one may immediately ascertain the relevant component at play.
Additionally, because most words consist of more than one character, typists will often require a multipart input code to account for multiple characters. In these scenarios, the input sequences for each individual character are separated by an em dash, which represents the location in which the typist must press the spacebar in order to initiate the next sequence of the input code. By way of illustration, consider the following multi-character examples taken from the Hwayih Woen edition of McGuffey’s First Eclectic Reader:
apple【苹果】
(廿)t02(一)m00(火)f04(十)j00—(田)w00(木)d00bonnet【软帽】
(大)k01(手)q03(弓)n09(人)o00—(中)l01(月)b05(日)a03(月)b04(山)u01chicken【鸡子】
(水)e03(心)p08(卜)y00(一)m00—(弓)n03(木)d03dinner【晚餐】
(日)a00(弓)n09(日)a02(山)u02—(卜)y01(水)e03(人)o00(戈)i01(女)v06etc.
Conclusion
Hwayih Woen is not a curiosity. It is not a mere demonstration or proof of concept. It is a serious proposition, made in full earnest, that the English language is not inexorably bound to the vagaries of the Latin alphabet, but can and should be fully embodied within Chinese characters, and ascend to the full linguistic might that such a logographic system can bestow upon a language. One cannot make such a proposition without a full awareness of the times in which a language resides. Indeed, mankind now lives in an age where any substantive language proliferation or reform must be able to fully operate within digital space without encumbrance. In effect, the computer keyboard has become the gatekeeper that any meaningful form of neography must pass. Fortunately, due to the valiant efforts of Chinese technologists in the previous century—bringing their hieroglyphic juggernaut into the age of the computer—monolingual English speakers who are trapped within the Anglosphere now have a way to participate in a cultural and linguistic milieu that was always traditionally unconcerned with the specific sounds that emerged from the human voice, which is a level of embodied inclusiveness that even the most fervent “social justice” advocates in the West have yet to conceptually fathom.
Romanized as “Cāngjié” in the Hànyǔ Pīnyīn system.